Reinforcement Learning as Probabilistic Inference - Part 2
Building on part 1, we establish decision-making as a probabilistic graphical model, connect RL to a trajectory prediction problem, and formulate optimal trajectory prediction as probabilistic inference.
Decision Making as a Probabilistic Graphical Model (PGMs)
Decision making problems (formalized as RL or optimal control), can be viewed as a generalized Probabilistic Graphical Model (PGM) augmented with utilities or rewards, that are viewed as extrinsic signals. PGMs are a mathematical framework for representing and reasoning about uncertain systems. It uses a graph-based representation as the basis for compactly encoding a complex distribution over a high-dimensional space. It turns out that graph as a representation of a set of independencies, and the graph as a skeleton for factorizing a distribution, are in a deep sense, equivalent! In this graphical representation, illustrated in the figure below, the nodes (or ovals) correspond to the variables in our domain, and the edges correspond to direct probabilistic interactions between them [1].
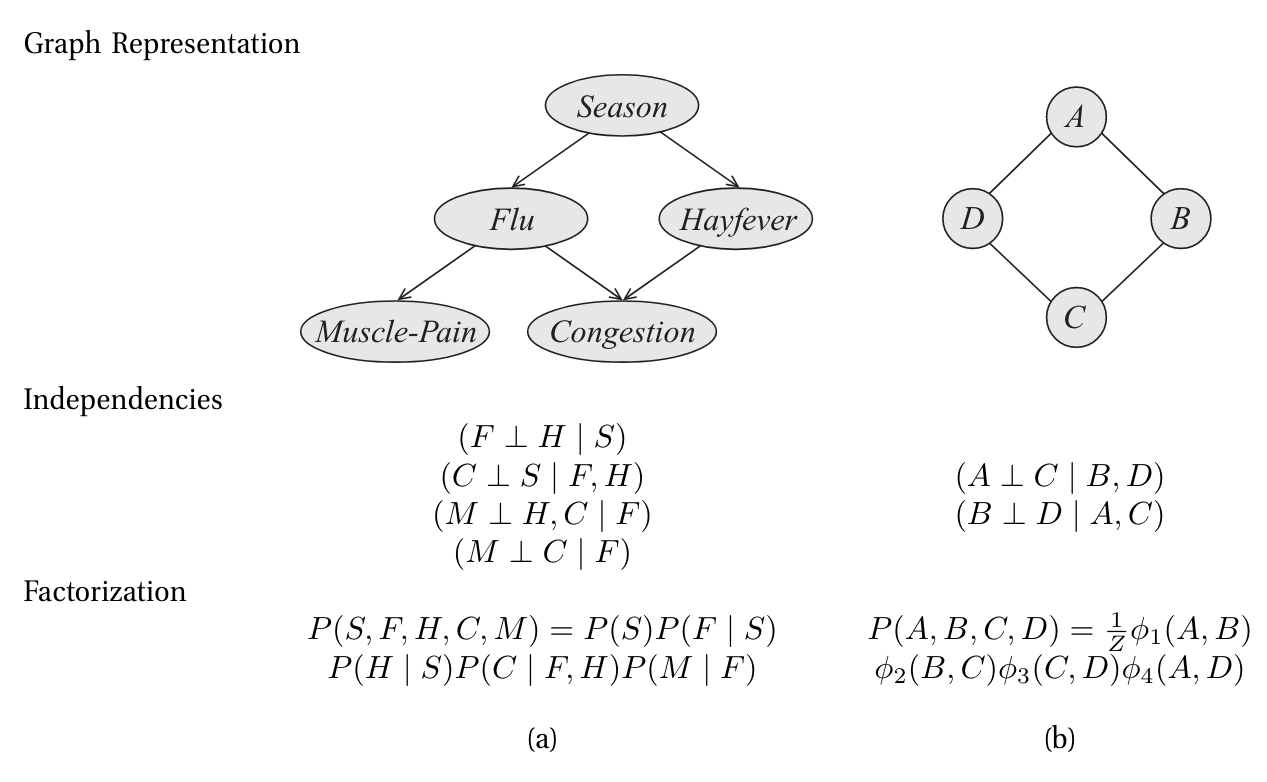
[1] describes two families of graphical representations of distributions; Bayesian networks represented with a directed acyclic graph and Markov networks, using undirected graphs. PGMs concisely represent independence properties and factorization structure of distributions.
Conditional interdependencies among variables are encoded as:
- D-separation in the directed graph for Bayesian networks.
- Separation in the undirected graph for Markov networks.
Factorization—how the joint probability distribution breaks into smaller, simpler components–—is explicitly represented as:
- Directed edges define the conditional probabilities in Bayesian networks.
- Cliques define the potential functions in Markov networks.
In the framework of PGMs, it is sufficient to write down the model and pose the question, and the objectives like parameter estimation, marginalization, or conditional probability computation arise directly from the graphical structure.
A common approach to solving decision making problems is to model the underlying dynamics as a probabilistic model e.g. with model-based RL, and determine an optimal plan or policy in a distinct process, e.g. trajectory optimization. In this frame, determining an optimal course of action or an optimal decision-making strategy (a policy) is considered a fundamentally distinct type of problem than probabilistic inference.
Reinforcement Learning Trajectory Prediction
Is it possible to cast the decision making problem into an inference problem using a particular type of PGM? [2] claims is it possible to formulate these two so that they return the same results ; a trajectory following a policy that we get from solving the sequential decision making task with RL and an optimal trajectory from conditioning on a probabilistic model trained on trajectory prediction.
The Decision Making Problem - standard RL formulation
We will use to denote states and to denote actions, which may each be discrete or continuous. States evolve according to the stochastic dynamics , which are in general unknown.We will follow a discrete-time finite-horizon derivation, with horizon , and omit discount factors for now. A task in this framework can be defined by a reward function . Solving a task typically involves recovering a policy , which specifies a distribution over actions conditioned on the state and parameterized by some parameter vector .
A standard reinforcement learning policy search problem is then given by the following maximization:
We are trying to find the vector of policy parameters that maximize the expectation of reward with state and action taken according to the policy, for each step t=1 to T across the trajectory. Lets express the random variable in terms of a distribution of trajectories. Starting with:
we can rewrite the expectation as a sum over all possible state-action pairs from to :
Recognizing that the sequence represents a trajectory , we can express this as:
where:
So this is the final expression we are trying to optimize in a standard reinforcement learning policy search problem :
Formulating the Decision-Making PGM
The next question we have to ask how can we formulate a probabilistic graphical model such that inferring the posterior action conditional gives us the optimal policy?
We have to introduce an additional binary random variable , which we call an optimality variable, to this model where denotes that time step is optimal, and denotes that it is not optimal.
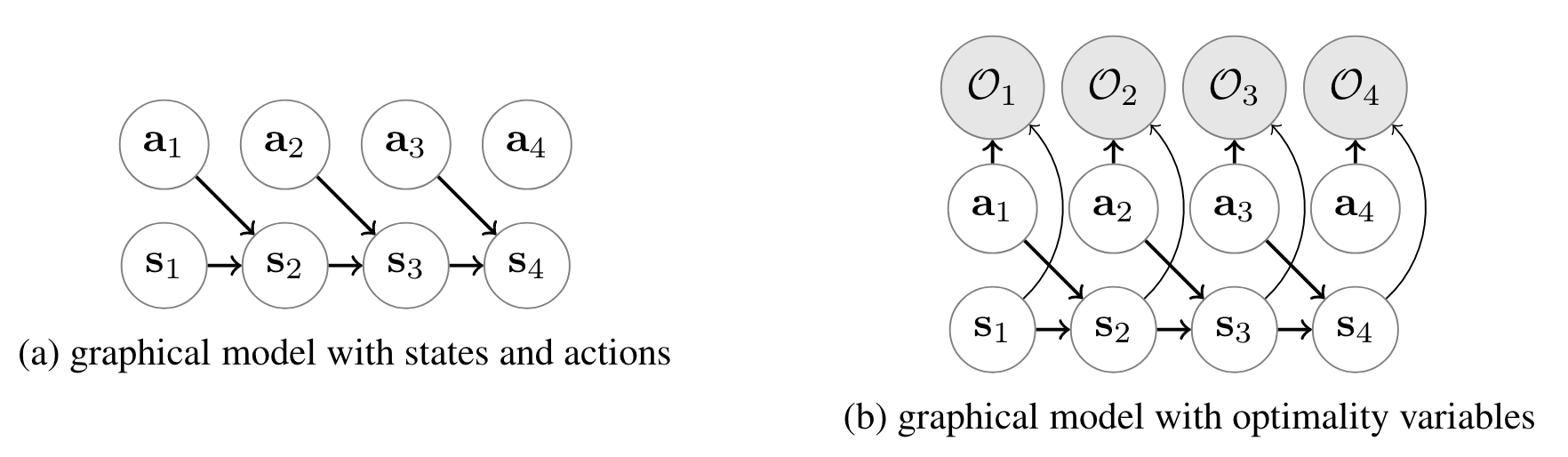
We will choose the distribution over the optimality variable as such:
This seems a bit arbitrary; why are we taking the exponent of the reward?
This form resembles the Boltzmann distribution in statistical mechanics, where probabilities are proportional to , with as energy and as temperature. Similarly, in reinforcement learning (RL), the reward plays a role analogous to negative energy, and taking ensures that higher rewards correspond to higher probabilities.
What this is really trying to get at is this — If represents the probability that time step is optimal, then the reward can be interpreted as a log-probability:
Exponentiating this ensures that the probabilities are normalized and non-negative. This approach is consistent with softmax-based action selection in RL, where the probability of choosing an action is proportional to . It allows smooth exploration by providing a probabilistic weighting over possible actions.
Planning = Inferring the optimal trajectory
From our PGM formulation with the optimality variable, we can infer the posterior probability of observing a trajectory given optimality for all steps in the trajectory. Given a policy (we haven’t optimized the policy parameters yet), if we would like to plan for an optimal action sequence starting from some initial state , we can condition on and choose . In other words, maximum a posteriori inference corresponds to a kind of planning problem!
- Probability of observing a given trajectory given that all steps are optimal: .
- Probability of trajectory occurring according to the dynamics: .
- Exponential of the total reward along the trajectory: .
* We are not directly concerned with the marginalization; instead, we want the unnormalized joint probability.
In the case where the dynamics are deterministic, the first term is a constant for all trajectories that are dynamically feasible. Here, the indicator function simply indicates that the trajectory is dynamically consistent (meaning that ) and the initial state is correct. So the probability of a trajectory occurring given all steps optimal is exponentially proportional to the sum of the rewards. In other words, the trajectory with the highest cumulative rewards would likely be the optimal trajectory, which is exactly what we want.
Recovering the Optimal Policy
Now we know how to find the optimal plan given a policy. We are not done yet. Remember from equation (1) that we are trying to find the optimal policy, where the expected cumulative reward across across all possible trajectories is maximized.
Lets first start by writing the optimal action conditionals within our probabilistic graphical model. This still assumes a fixed policy that is not necessarily optimal.
Before we go ahead, we want to make the distinction between the optimal action conditionals and the action conditionals given the optimal policy (which is the expected outcome of a standard RL frame), as the optimal action conditional is independent of the parameter . Nevertheless the optimal action conditional and action conditionals given the optimal policy both aim to select actions that lead to optimal outcomes and are therefore closely related. We will continue deriving the optimal action conditional in part 3!
References
- D. Koller and N. Friedman, Probabilistic Graphical Models: Principles and Techniques, Nachdr. in Adaptive Computation and Machine Learning. Cambridge, Mass.: MIT Press, 2010.
- S. Levine, “Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review,” 2018.